Published and Accepted Peer-Reviewed Articles
Does working from home work? A natural experiment from lockdowns
European Economic Review, 20231 / 5
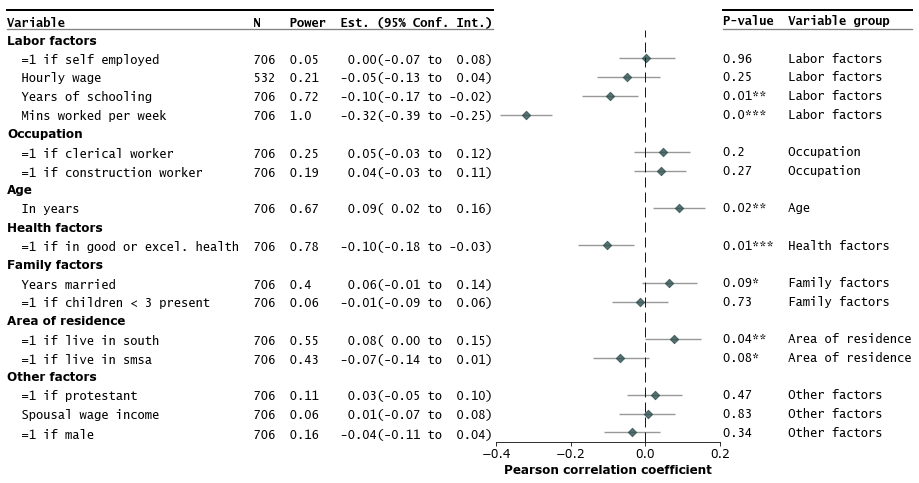
Change in output (tracked changes)
2 / 5
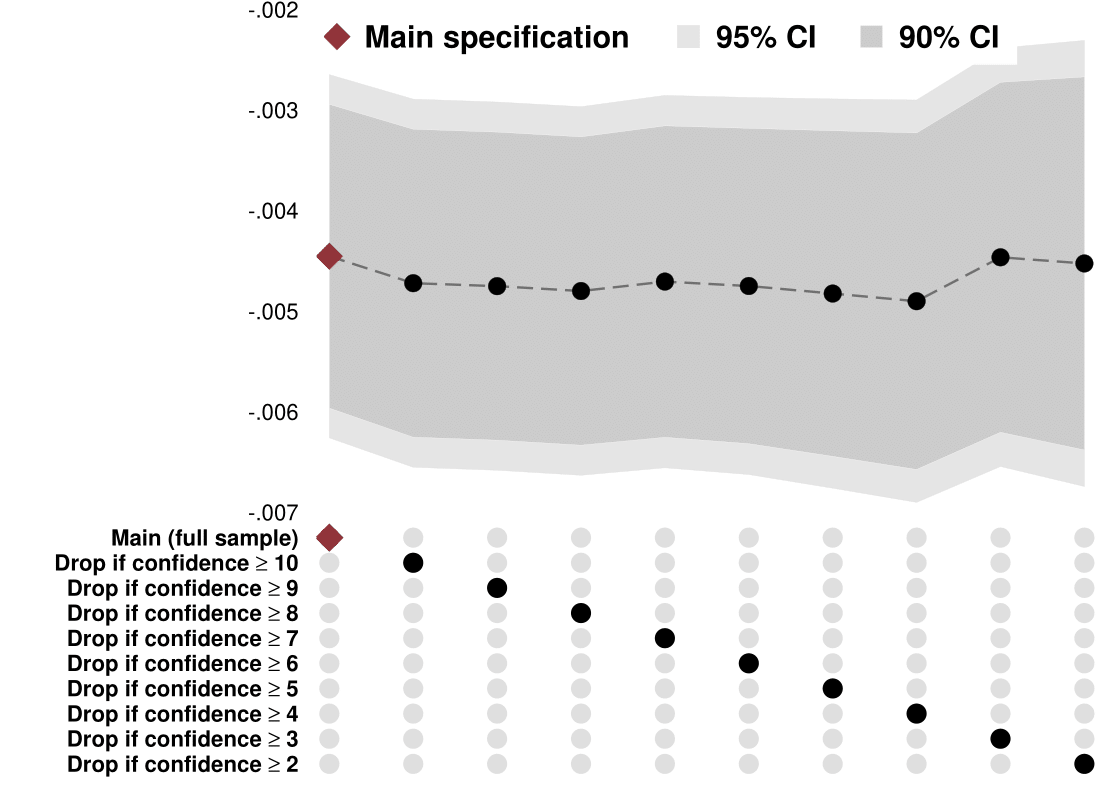
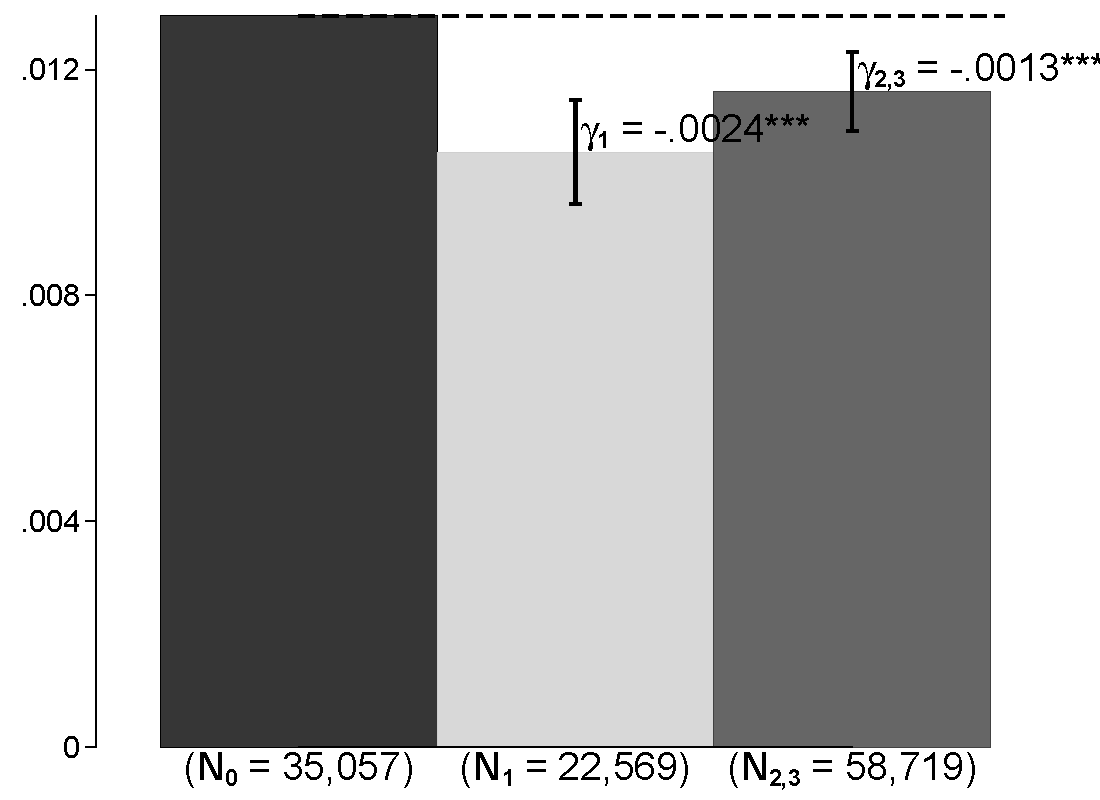
Sensitivity to geocoding
3 / 5
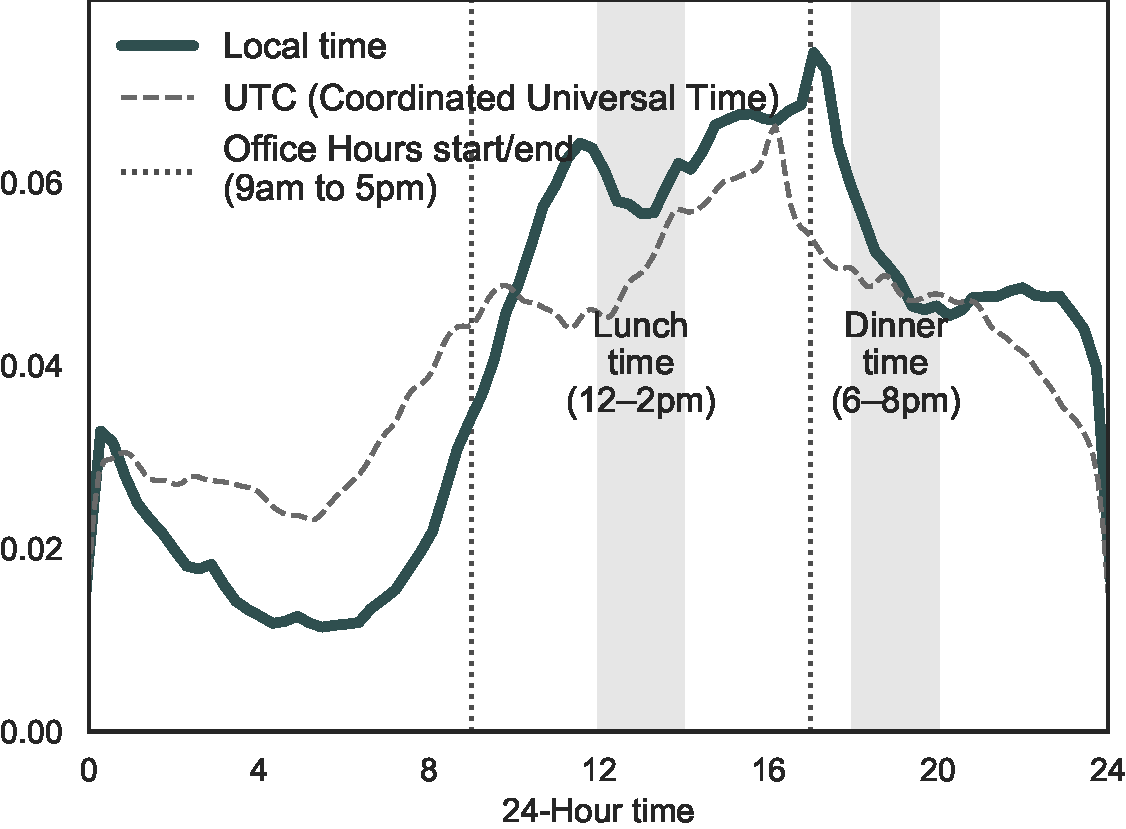
Standard vs local time
4 / 5
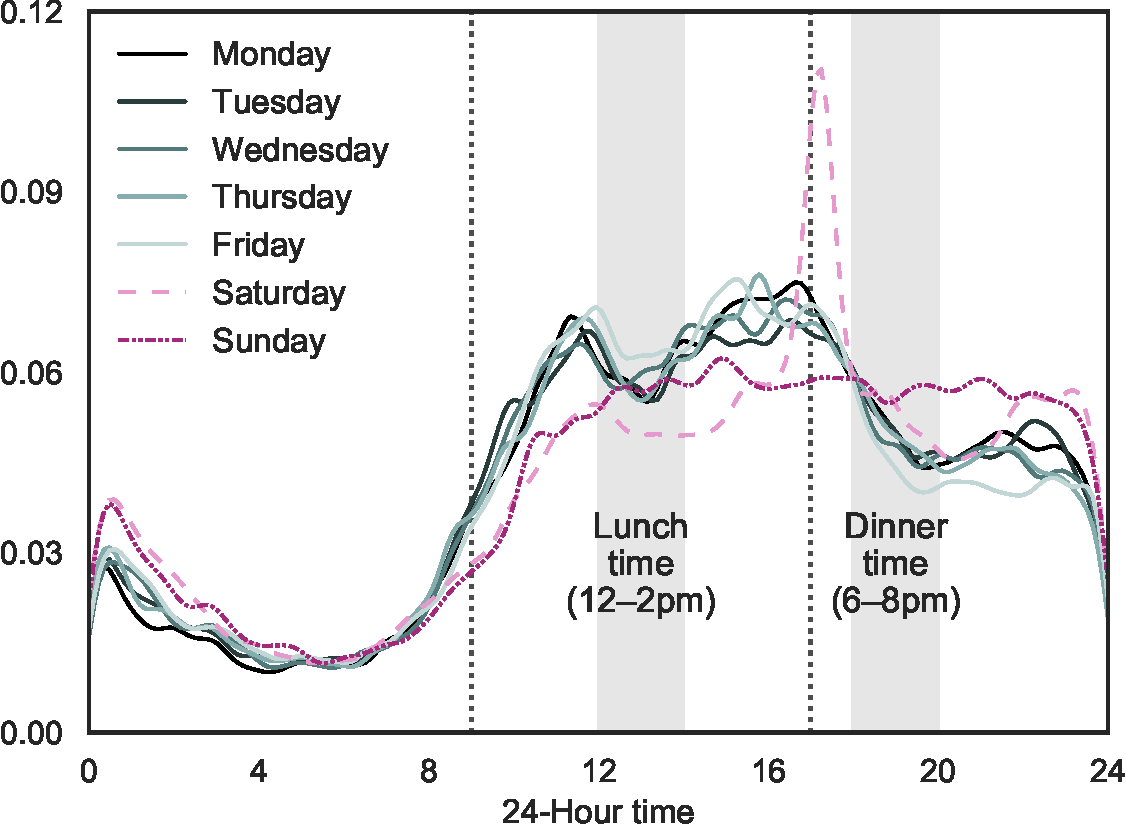
Local time by hour-of-day
5 / 5
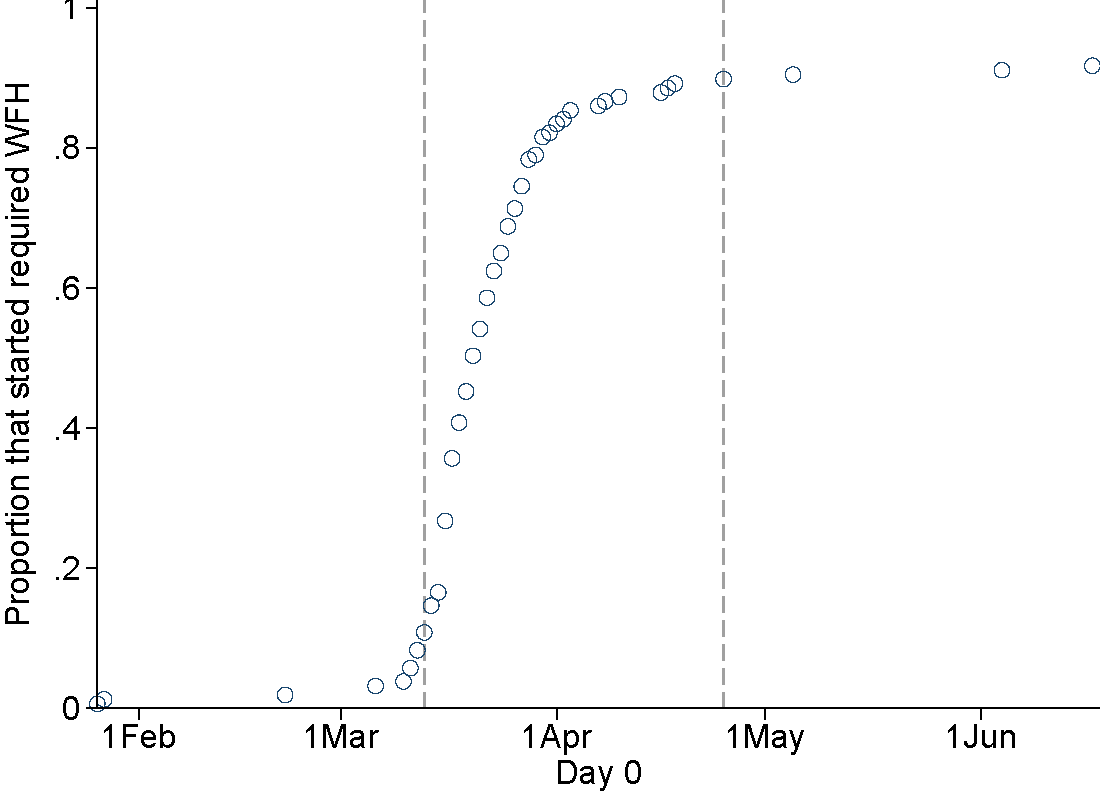
Global rollout of lockdowns
Holier Than Thou? No Large Partisan Gaps in the Consumption of Pornography Online
(with Gaurav Sood)Journal of Quantitative Description: Digital Media, 2024



Illegal Immigration and Infections: Evidence from Two Modern Pandemics
Economic Modelling, 2025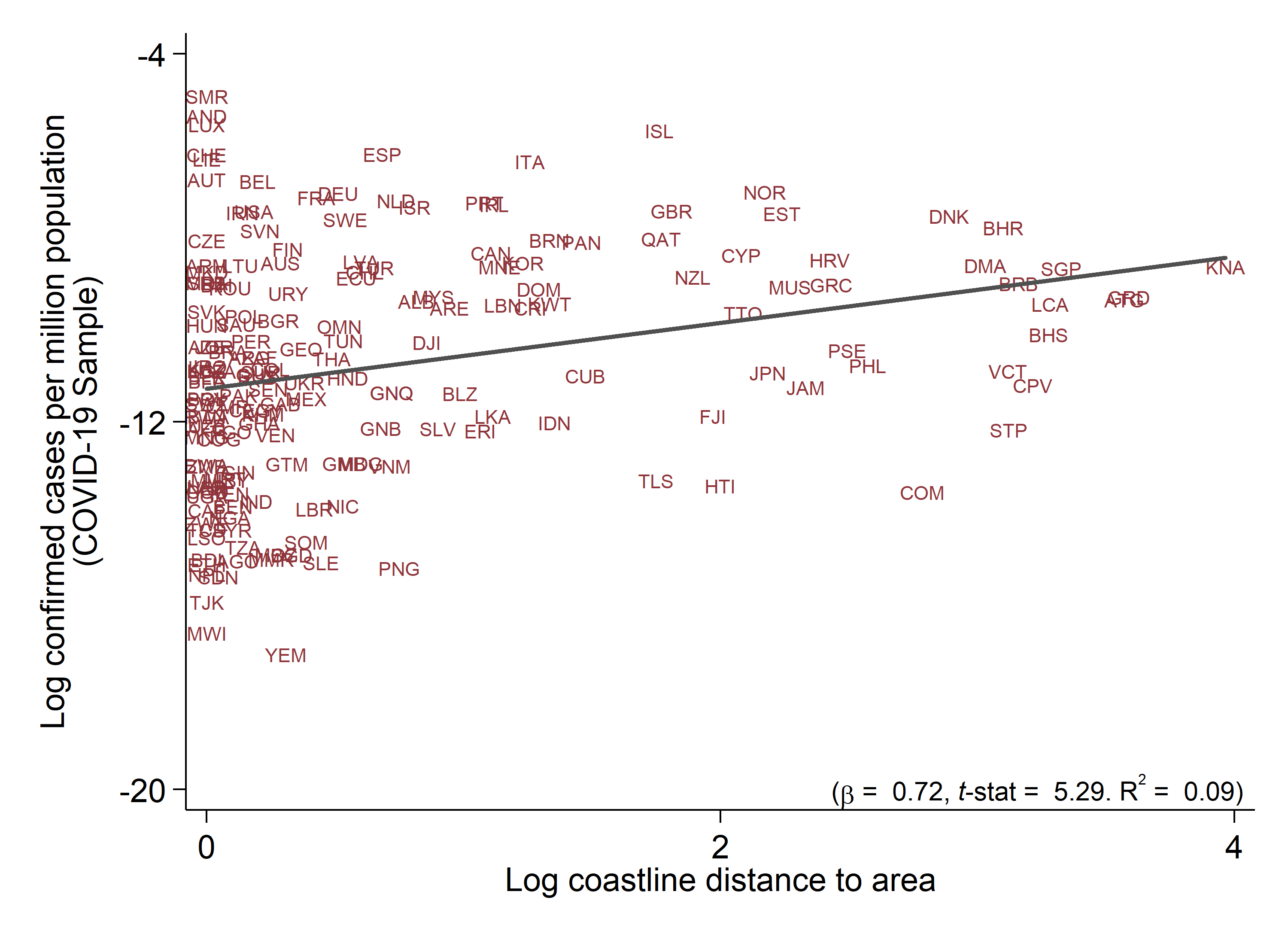
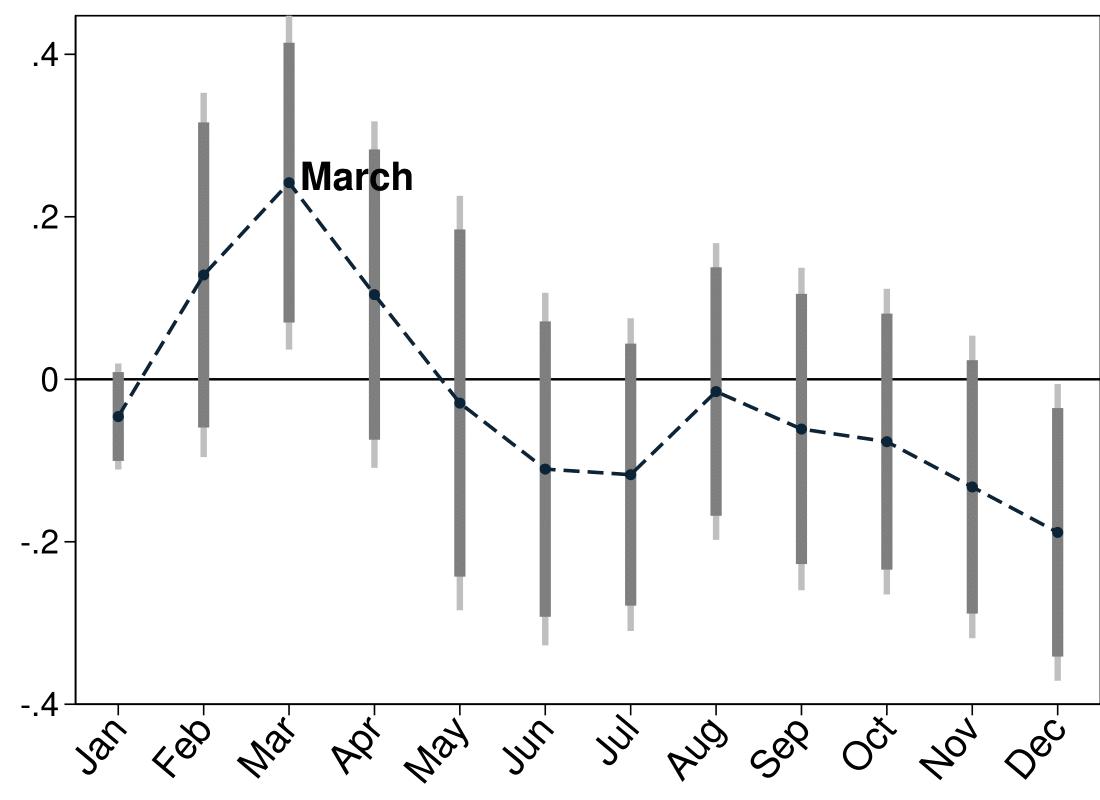
A Measurement Gap? The Effect of Survey Instrument and Scoring on the Partisan Knowledge Gap
(with Gaurav Sood and Daniel Weitzel)Public Opinion Quarterly, 2025
1 / 2
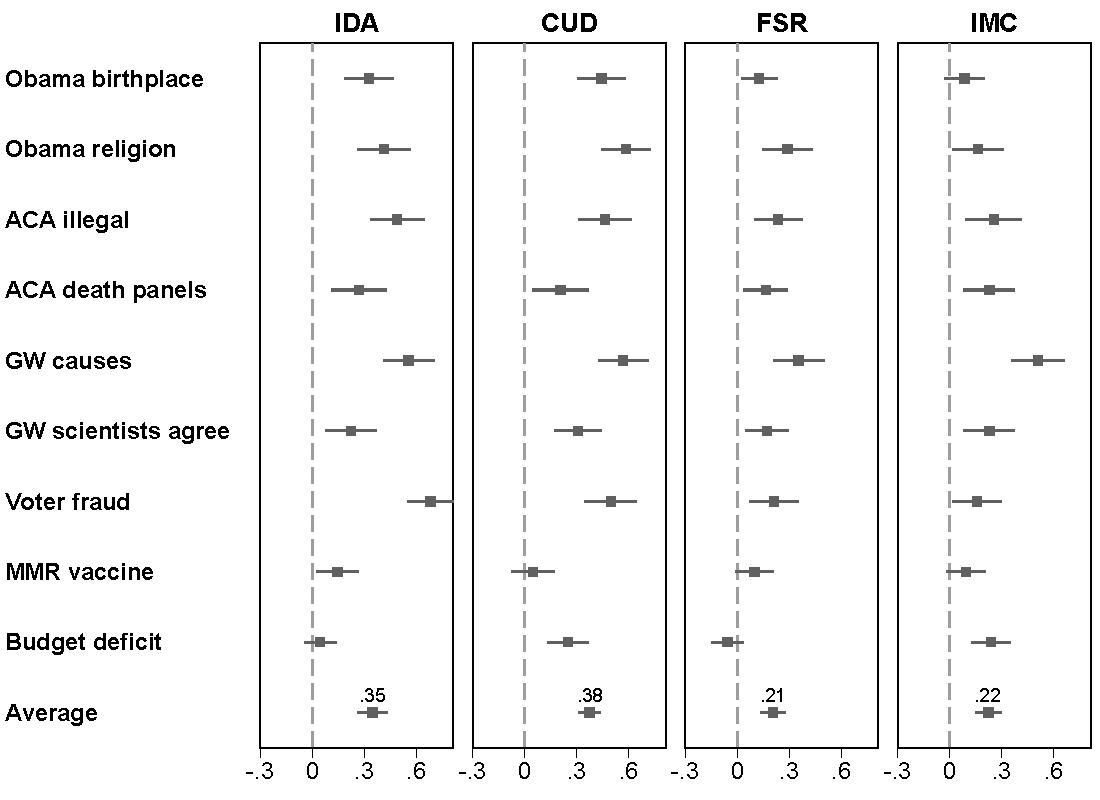
Knowledge gaps by different treatment groups and items
2 / 2

Weighted estimate of inflated partisan gaps
Shades Of Neutrality: Detecting Media Slant In A Political Monopoly Using Quotation Accuracy
[Accepted, ACM Transactions on Intelligent Systems and Technology]



Residential proximity to transport facilities as urban determinants of individual-level per- and poly-fluoroalkyl substance (PFAS) exposures: Analysis of two longitudinal cohorts in Singapore
[Accepted, Environmental Health]



Social Proof is in the Pudding: The (Non)-Impact of Social Proof on Software Downloads
(with Gaurav Sood and Daniel Weitzel)[Accepted, Journal of Online Trust and Safety]
Bad Domains: Exposure to Malicious Content Online
(with Gaurav Sood)[Accepted, Information, Communication & Society]
Deconstructing the MeToo Movement and the Blue Wave in the 2018 House Elections
[Accepted, Computational Communication Research]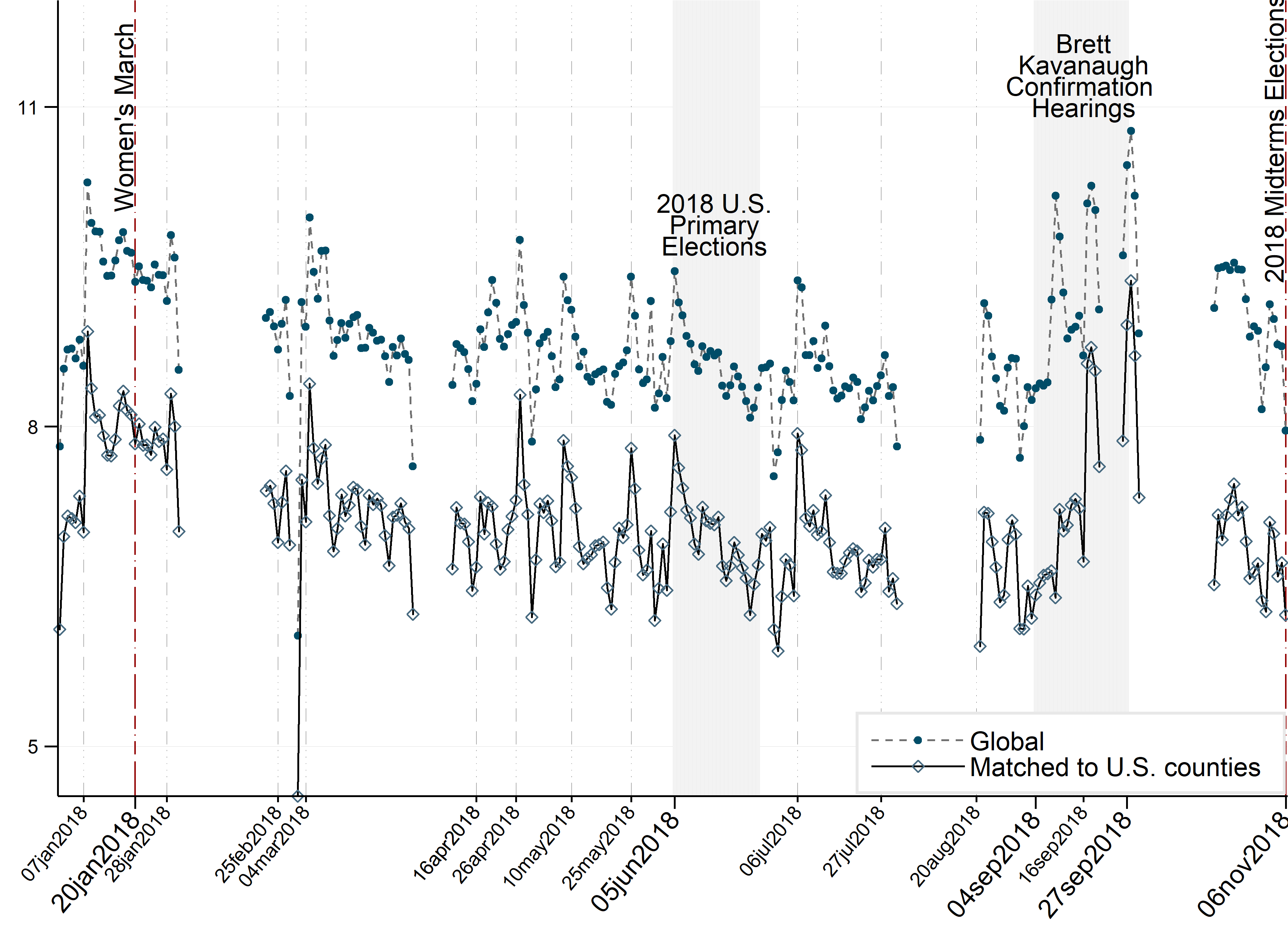
Working Papers
Neighborhood Mismatch and Visits
December 2024 (with LIM Jing Zhi)1 / 4
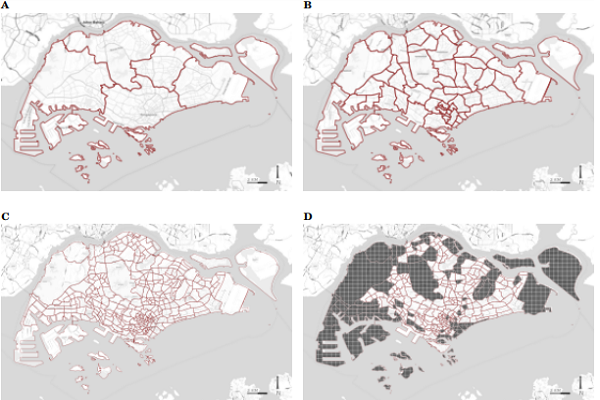
Scale & borders in the Singapore context
2 / 4
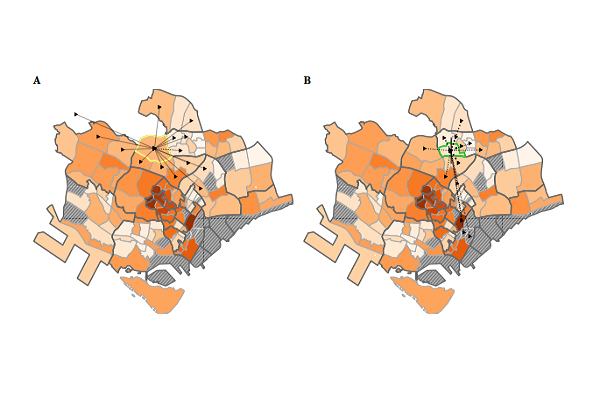
Two neighbourhoods (Mount Pleasant & Toa Payoh Central)
3 / 4
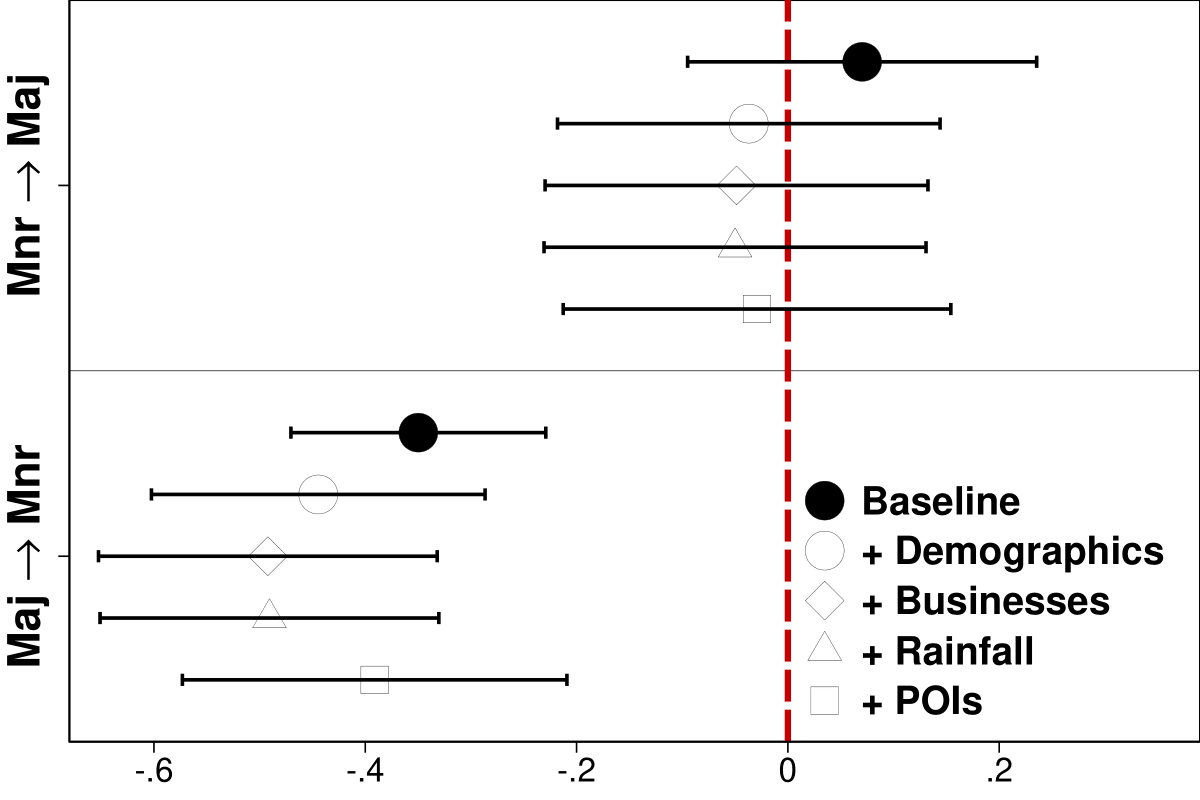
Asymmetries in mismatch and visits
4 / 4
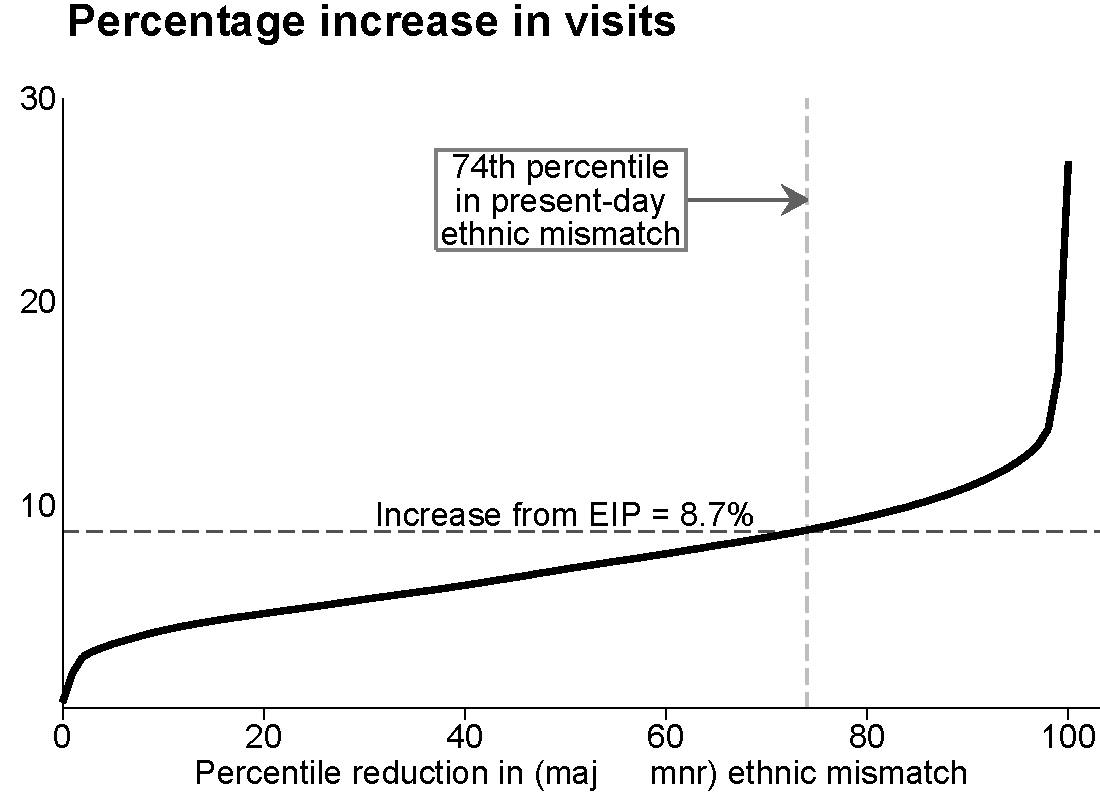
EIP and increases in neighborhood visits
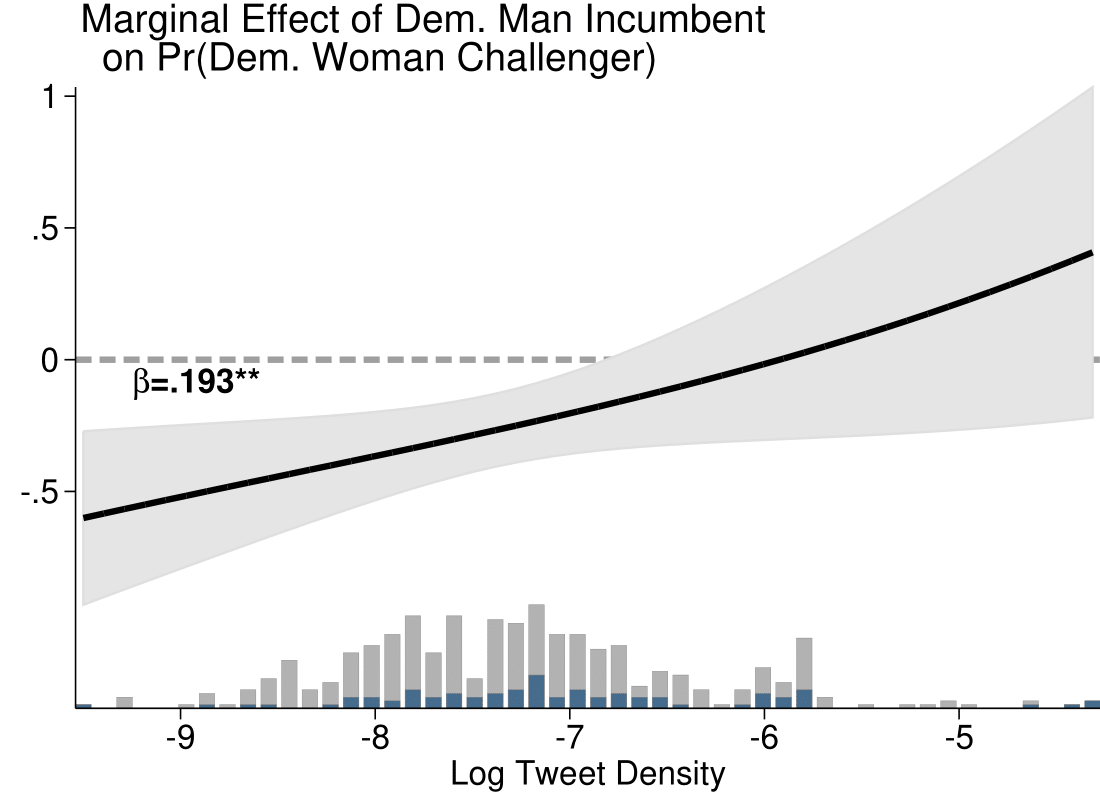
How Often is Politicians' Data Breached? Evidence from HIBP
Mar 2025 (with Gaurav Sood)Exposed: Shedding Blacklight on Online Privacy
Dec 2025 (with Gaurav Sood)Parks, pedestrians, and pediatric adiposity: A spatiotemporal analysis in an urban longitudinal cohort
1 / 1

Transient Buffering Effects of Park Accessibility Against Movement Control Policies on Child Weight Status: A Quasi-Experimental Analysis
1 / 2

Spatial distribution of residential park access
2 / 2

Event-study DiD: BMI by park access (relative to 2019)
Other Publications & Projects
Social Exposure Zones in a Small City
(with LIM Jing Zhi)Income and Productivity Trends of Guangdong: A Data-Driven Case Study of the Greater Bay Area
October 2022 (with LI Jingwei and ZHANG Xuyao)1 / 1
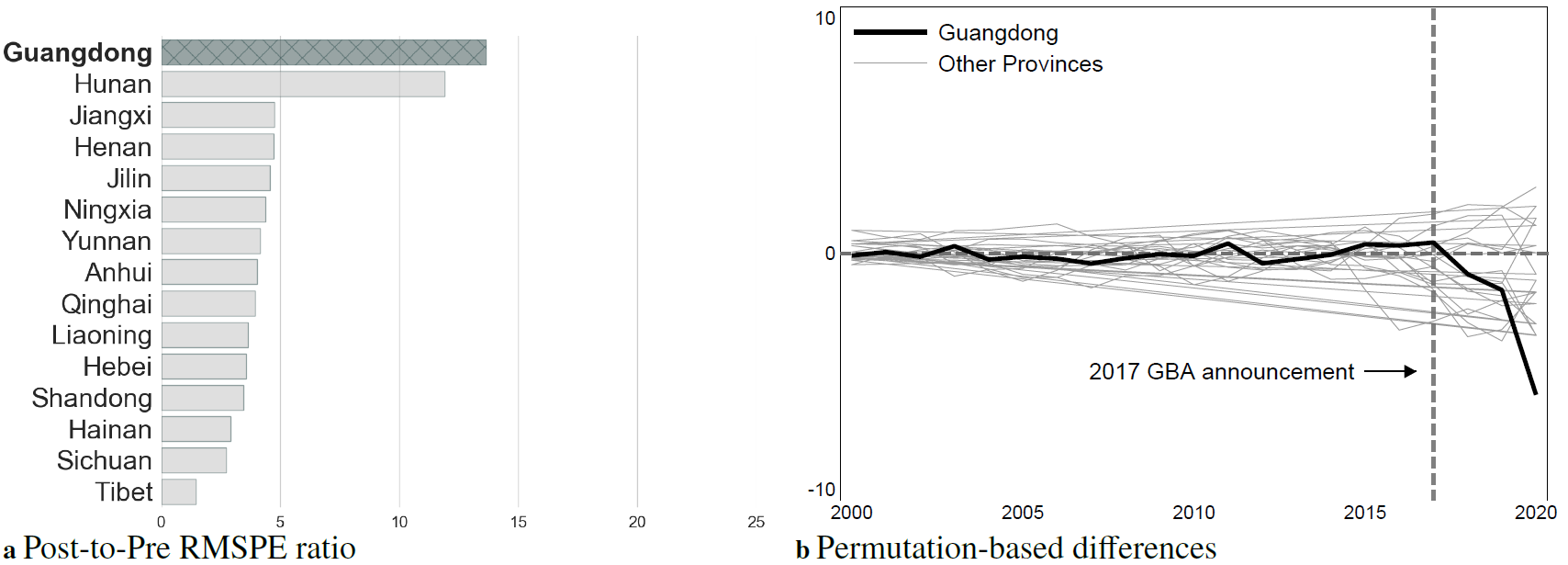
Permutation tests
Segregation Across Neighborhoods in a Small City
(with LEE Shu En, LIM Jing Zhi)[*Superceded by Neighborhood Mismatch and Visits]
Unexpected Shocks to Movement and Job Search: Evidence from COVID-19 Policies in Singapore Using Google Data
1 / 3
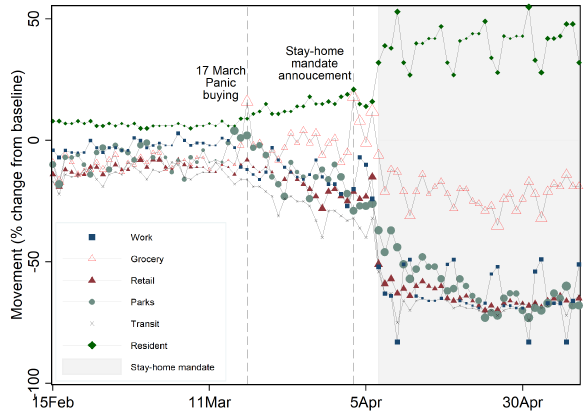
Early changes (anomalies) in movement patterns
2 / 3
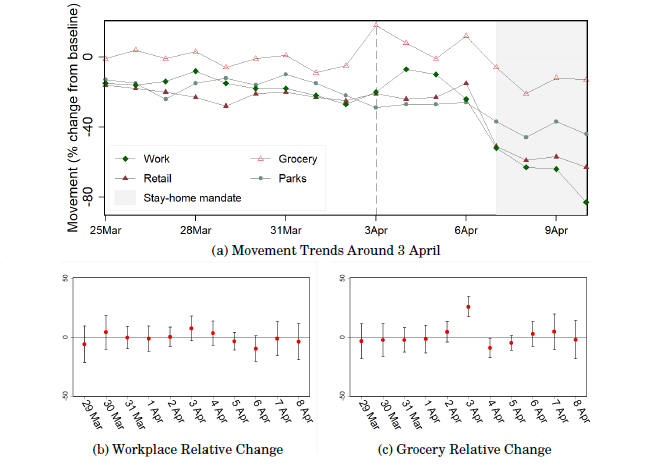
Lockdown announcement effect
3 / 3
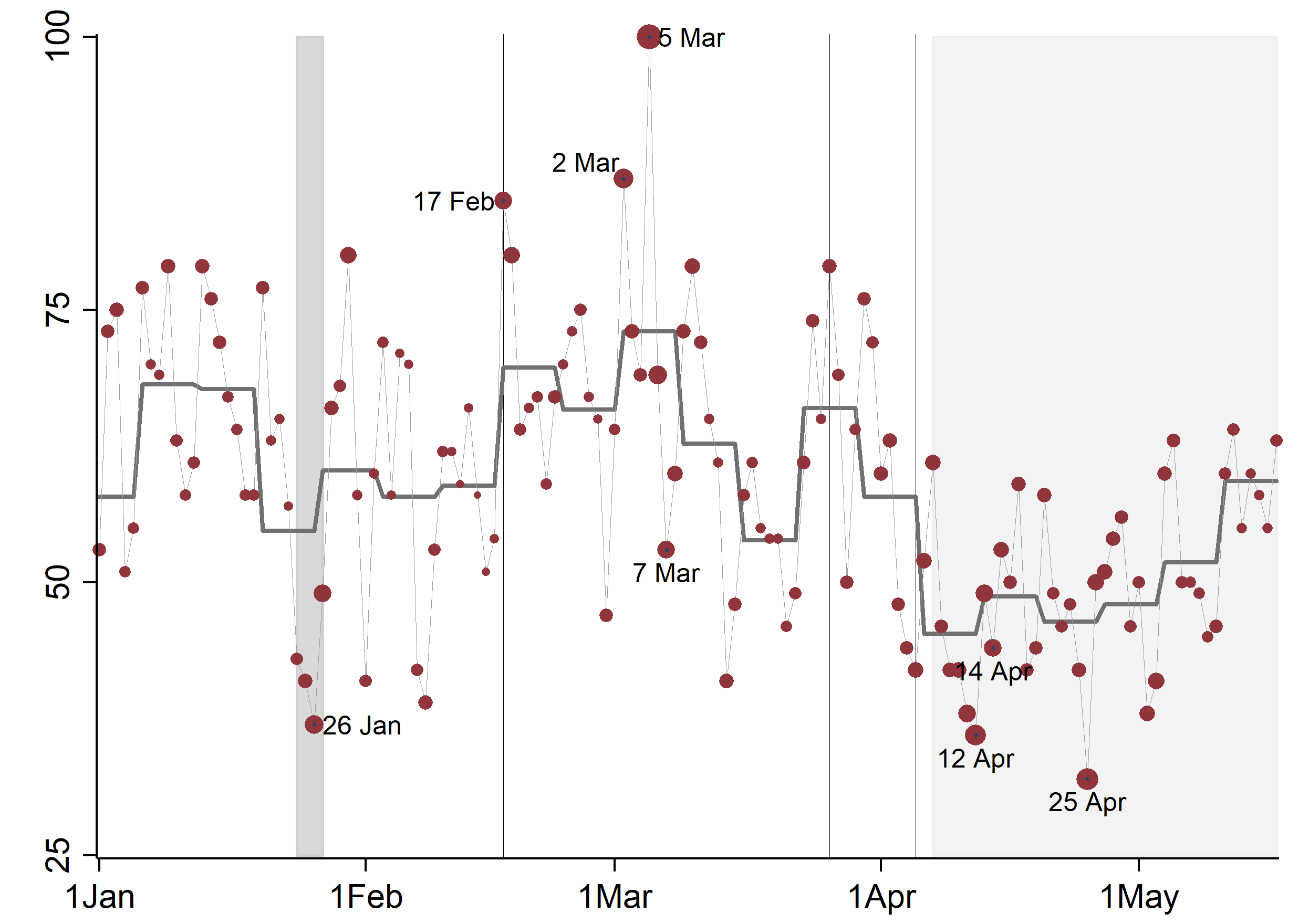
Early changes in job searches